LangGraph Agents For SHAP — LLM
In a previous article I had detailed how I designed a sequential agent system using LLAMA 3 with ollama, which would create automated reports including top reasons for churn and top recommended actions to minimize churn from telco dataset. The results from this simple agent system was surpringly good. However there were few challenges still that existed with this agent system:
- The RAG architecture was simple top K fetch. Hence the retrived documents for the LLM were not always ideal
- There were no checks in place to prevent hallucination by agents (temperature was set to 0, but still agents incorrectly explained one feature effect)
- There was no feedback in the system. There question had to be framed properly for optimal result. This required multiple iterations of manual runs
This made me look for a better solution which could be applied to any dataset. I wanted to use local LLMs still, in this case Llama-3 specifically, but wanted to implement an agent architecture with all the above listed features added. Few days of back and forth brought me to LangGraph. This is such an easy and great framework created by langchain team, which let’s us design any structure of our interest with a few lines of code. They have provided some great documentation and tutorials for easy implementaion with different LLMs. In addition to this we can track and monitor our agent using LangSmith.
Implementation:
The major updates made withy this new approach are:-
- Using adaptive RAG framework to limit context to relevant documents, prevent hallucination, cyclic question transformation etc.
- Adding the Business Analyst and Manager Agent as nodes within a langgraph
- Tracking the agent system with LangSmith
I have used the adapative RAG framework explained by langchain team in a great tutorial to modify my retrieval system. Below is the graph developed for SHAP LLM
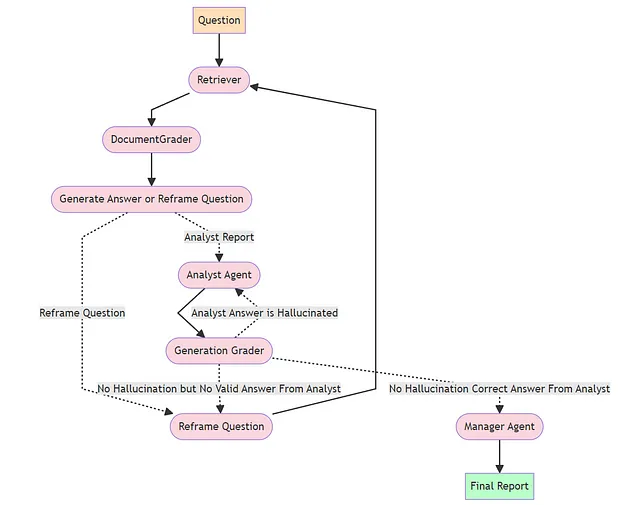
- Retriever : Fetches top k documents by embedding similarity to question from the Chroma DB of documents
- Document Grader : Every document passed by retriever to the question will be checked one by one for relevance to question by a Llama3 Agent. Only the documents that have relevance to question determined by the agent will be passed further. I have noticed smaller chunk sizes work great here which was a very bad option with simple RAG.
- Reframe Question : If the document grader considers all documents passed by retriever to be non-relevant, then another agent will reframe the question and try again. For example if the question “What are the top reasons for Churn?” doesn’t return any relevant document, agent will try with “What are the primary drivers of customer turnover?
- Generate Answer : If the document grader returns atleast one relevant document, then it is passed to the Business Analyst Agent. This agent will create a report from the context passed answering the question. The answer from Analyst Agent is passed to Generation Grader System. There are 2 agents here 1. Hallucination Grader 2. Answer Relevance Grader
- Hallucination Grader : This agent looks at the report created by Analyst and compares to the the context documents. It makes sure that the report is based on ground truth and no agent hallucination is added. If there is hallucination it will asked Analyst to recreate the report
- Answer Relevance Grader : If there is no hallucination, this agent will check the relevance of answer from Analyst to the question. If there is no relevance, this agent will create flow to reframe the question and try again. If the answer is relevant, then the agent will pass the answer to Manager Agent
- Manager Agent : This agent will take the report generated by Business Analyst agent and does proof reading and formatting. Eventually the final report to be shared with executive team is generated by this agent based on the question passed.
Lang Smith Trace:
I used the same Telco Churn dataset for the SHAP LLM here. You can track the whole architecture on the 2 questions passed here:
- question: What are the top reasons which increases the probability of class 1? https://smith.langchain.com/public/9af20925-9e46-4e25-8a86-b2c3f3f26d3d/r
- question: What are 5 recommended actions to increase retention or to reduce churn? https://smith.langchain.com/public/60a065ba-952e-4b2f-8b9e-5e728698bf8e/r
Next Steps:
The adaptive RAG with Langgraph is a big improvement to simple sequential agents. However one thing I noted is that the SHAP information and feature contribution can be bit much for a retriver to accurately pass on. The prompt design is still a very important factor here. Wording prompt to match how the shap summary document is generated play a key role in proper answer generation. However in our case for any SHAP explanation, we want to make it less prompt dependent. The best option I could think of here is to use a relational database instead of vector database. Using LLM create SQL queries to extract the information we need from SHAP saved as a table. The use this information for the report generation. As next step I would try to implement this idea, so the approach could be global on any dataset and not heavily prompt dependent.