Enhancing Model Interpretability: Using LLMs with SHAP Values in Call Centers
Introduction
Advancements in AI have rapidly evolved from simple models to complex Large Language Models (LLMs). This article explores using LLMs with SHAP (Shapley Additive Explanations) values to enhance model interpretability, helping end-users, particularly call center agents, understand model predictions effectively. The AI landscape has progressed significantly from the days when linear regression models were considered cutting-edge AI, with new updates being released every few weeks.
With the new plethora of LLM models now available from multiple open sources, I wanted to explore a use case that could help data scientists maximize the value of their models for end users.
Application of SHAP Values in Call Centers
In most projects I’ve worked on, models were evaluated not just by accuracy standards but also on interpretability. SHAP values have been my go-to tool for this purpose, providing explanations for black box model predictions both globally and locally. However, these insights often remain confined to the developer side, primarily because end users might not be technically oriented, and understanding SHAP value output isn’t particularly intuitive, especially at the local level.
It’s crucial to understand that SHAP isn’t performing causal analysis—it’s explaining predictions made by the XGBOOST model. While correlation doesn’t imply causation, properly explained correlations can help identify or point toward potential causes.
System Architecture and Data Handling
In our case study, the end user is a call center representative focused on increasing customer retention. We’ve created an AI agent to assist the rep with relevant customer information. When a customer profile is loaded, the system explains:
- Customer identity and profile
- Customer’s churn likelihood
- Factors contributing to the predicted churn likelihood
- Recommended actions to increase retention
For testing this approach, we used the publicly available Telco churn dataset, containing information about 7,000 customers. We created a simple XGBoost model using an 80-20 data split, achieving an 84% AUC. While the model could be further improved, our focus was on creating an infrastructure to help the AI agent assist representatives effectively.
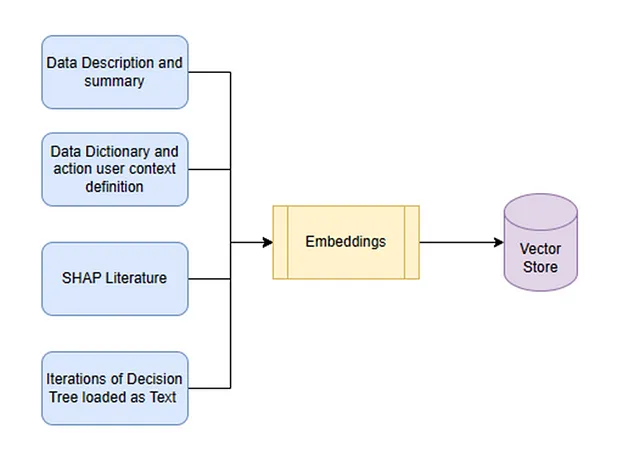
Information Store Creation
For GPT models to answer questions accurately, they need training with relevant information. We created four different documents:
- Data summary : Using an automated function create a file that explains the type of each features, distribution and percentiles
- Data dictionary and context : This has to be manual file and very important to be detailed as possible. We will pass the descriptions of each features used and the groups of user contexts and action contexts. Grouping them into different context space is important so that LLM can identify what action could be performed.
- SHAP Literature : This is optional but would not hurt. We pass information about what SHAP value is and how to interpret SHAP value from different sources
- Iterations of Decision Tree loaded as Text : We have created the model using XGBOOST and SHAP is based on that model. However to help the agent with recommended actions this might not be enough. So we will run N iterations of decision tree over the data with different feature space used each time. For each iteration we will convert the tree logic into a text file and append each iterations over. Idea is that the LLM after learning from the users action context could decide which action would help improve retention from this tree logic available as text. Granted this is not a fool proof method and we can implement better alternatives for this purpose like a simulation of XGBOOST model on action space for each records. But this looks like a simpler approach and goes in line with the general idea.
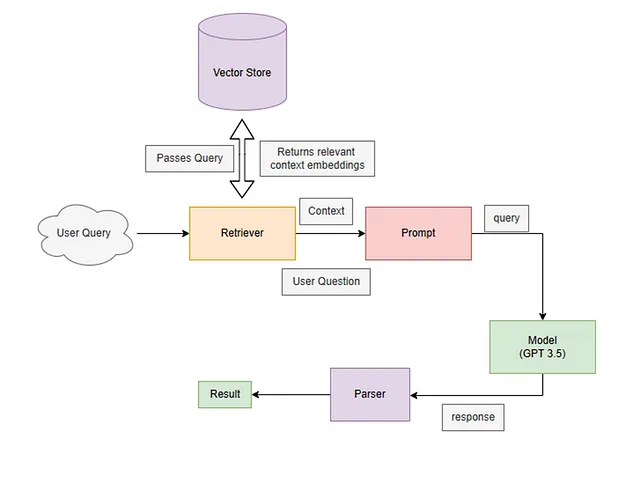
RAG Framework Implementation
Rather than fine-tuning the model, we implemented RAG (Retrieval Augmented Generation). The RAG system:
- Retrieves relevant documents using vector similarity search
- Combines retrieved texts with the original query
- Generates contextually appropriate responses using both query and retrieved documents
SHAP LLM Workflow
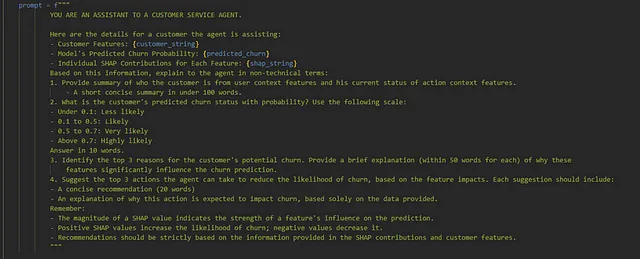
The prompt design is crucial for our AI agent. We include:
- Customer string : A string of all the features of the customer used in prediction
- Predicted Churn : What was the predicted probability byb model for churn
- SHAP string : The SHAP feature contribution to churn for all features of the customer
Here is a snap of the prompt we use for the AI agent:
We design the prompt to provide the responses to the 4 questions we want to help the agent. Here is the structure of the whole workflow:
Results and Insights
After testing the system with 100 customers from our test sample, we observed:
- Using GPT-3.5, we processed 100 customers in approximately 2 minutes at a total cost of $0.08
- GPT-4 produced better results with lower context space but at significantly higher cost
- GPT-3.5 occasionally overemphasized SHAP value magnitudes, which could be improved with richer context
- Recommended actions sometimes included generalized information, suggesting room for improvement in decision tree input or simulation approach
The results can be viewed at: SHAP LLM for Customer Service
Future Improvements
Potential areas for enhancement include:
- Testing with locally hosted LLAMA3/ DeepSeek /Qwen model
- Optimizing vector space and prompt engineering
- Improving the decision tree text input methodology
- Developing a more sophisticated simulation approach for the model with action space

